Learning Spherical Convolution for Fast Features from 360° Imagery

We propose a generic approach that can transfer Convolutional Nerual Networks that has been trained on perspective images to 360° images. Our solution entails a new form of distillation across camera projection models. Compared to current practices for feature extraction on 360° images, spherical convolution benefits efficiency by avoiding performing multiple perspective projections, and it benefits accuracy by adapting kernels to the distortions in equirectangular projection.
[top]Preliminary
Existing strategies for applying off-the-shelf CNNs on 360° images are problematic.
Strategy I
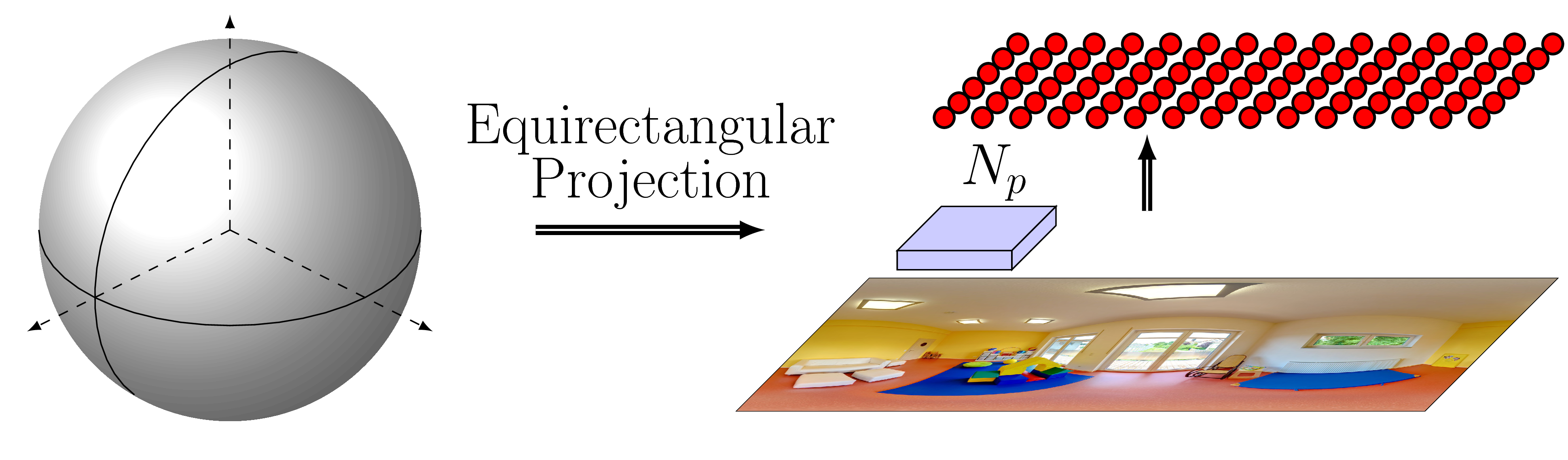
- Accuracy: inaccurate in regions where the visual content is distorted
- Efficiency: computationally efficient, because the only overhead is the sphere-to-plane projection
Strategy II
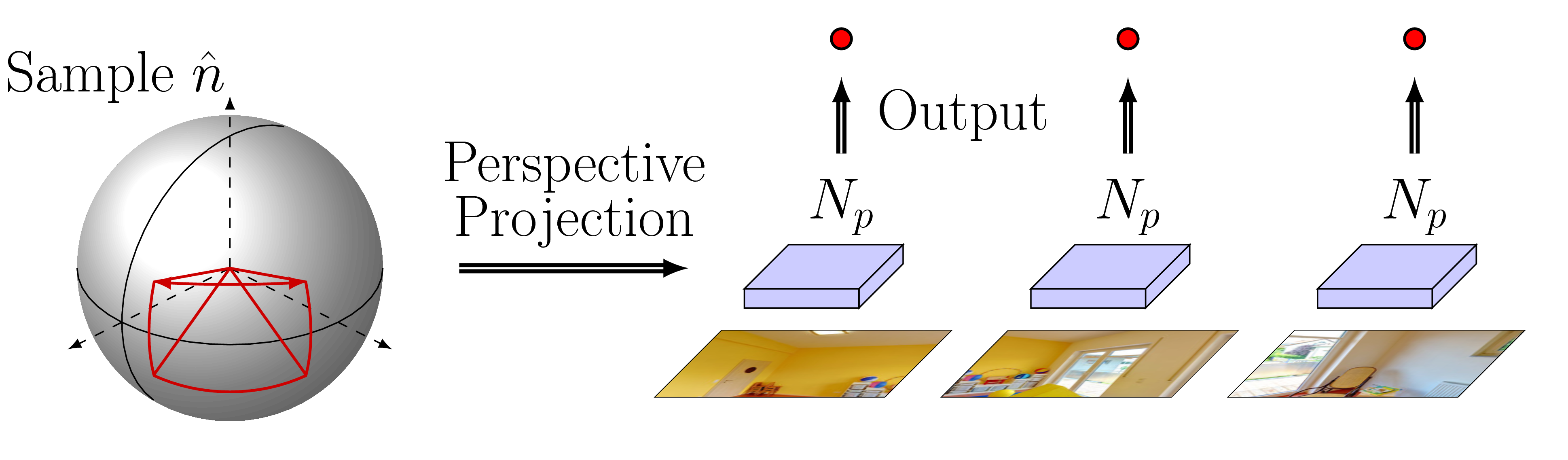
- Accuracy: as accurate as the source model, because there's no distortion
- Efficiency: high computational cost, because it requires repeated projection and model evaluation
Spherical CNN
Many works try to learn new CNNs on spherical data. However, they require annotated training data in spherical format and cannot exploit existing datasets and models even for the very same task.
[top]Spherical Convolution
Objective
We learn the spherical convolutional network to reproduce the exact outputs of the source model on the perspective projected images while taking the equirectangular projection as input.
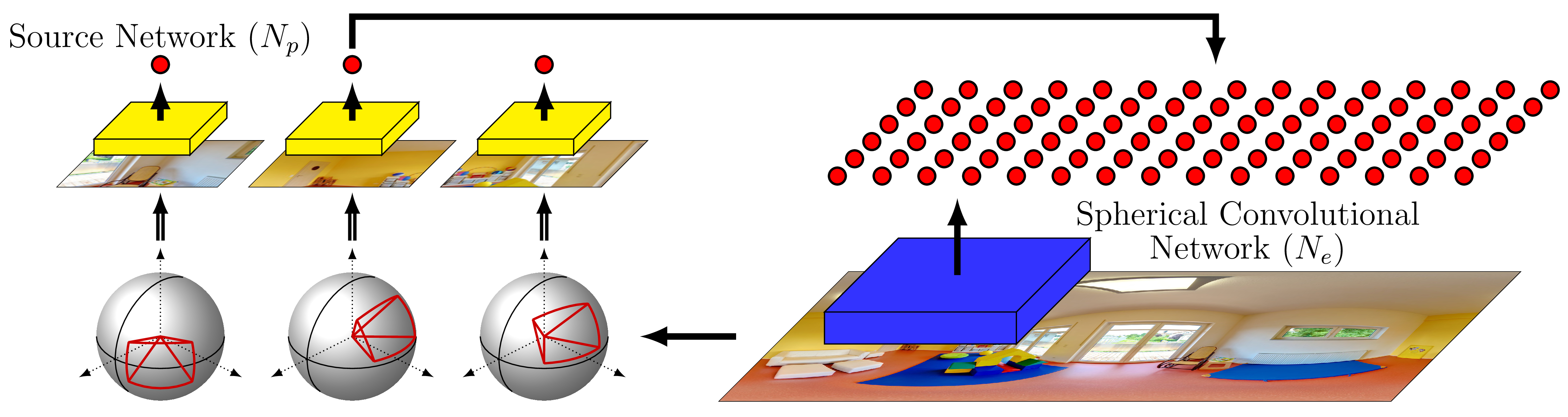
- Accuracy: spherical convolutional network is accurate, because it reproduces the outputs of the source model on the undistorted (i.e. perspective projected) visual content
- Efficiency: spherical convolutional network is efficient, because it convolves over a single equirectangular projection
Network Architecture
Because the distortion in equirectangular projection is location detendent, we untie the kernel weights along the rows. The kernels learn to account for the different distortions they encountered.

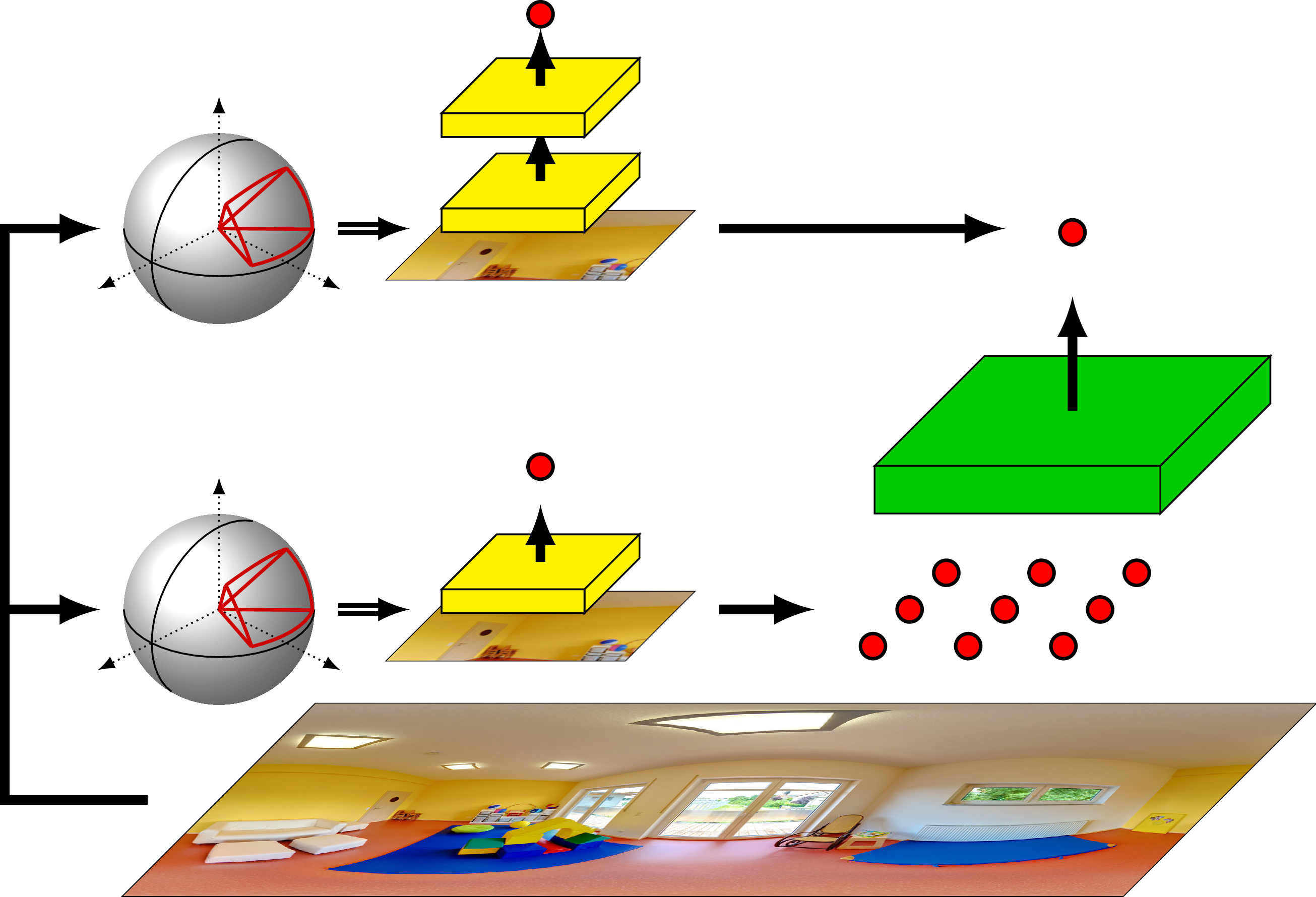
Layer-wise Training
We propose a layer-wise training procedure to accelerate learning. By requiring the spherical convolutional network to reproduce all intermediate outputs of the source model, each layer of the network becomes independent and can be trained separately.
Results
To evaluate the method, we apply SphConv to off-the-shelf Faster R-CNN. We train the model on the Pano2Vid 360° video dataset and evaluate on the Pano2Vid and spherical Pascal VOC 2007 datasets.
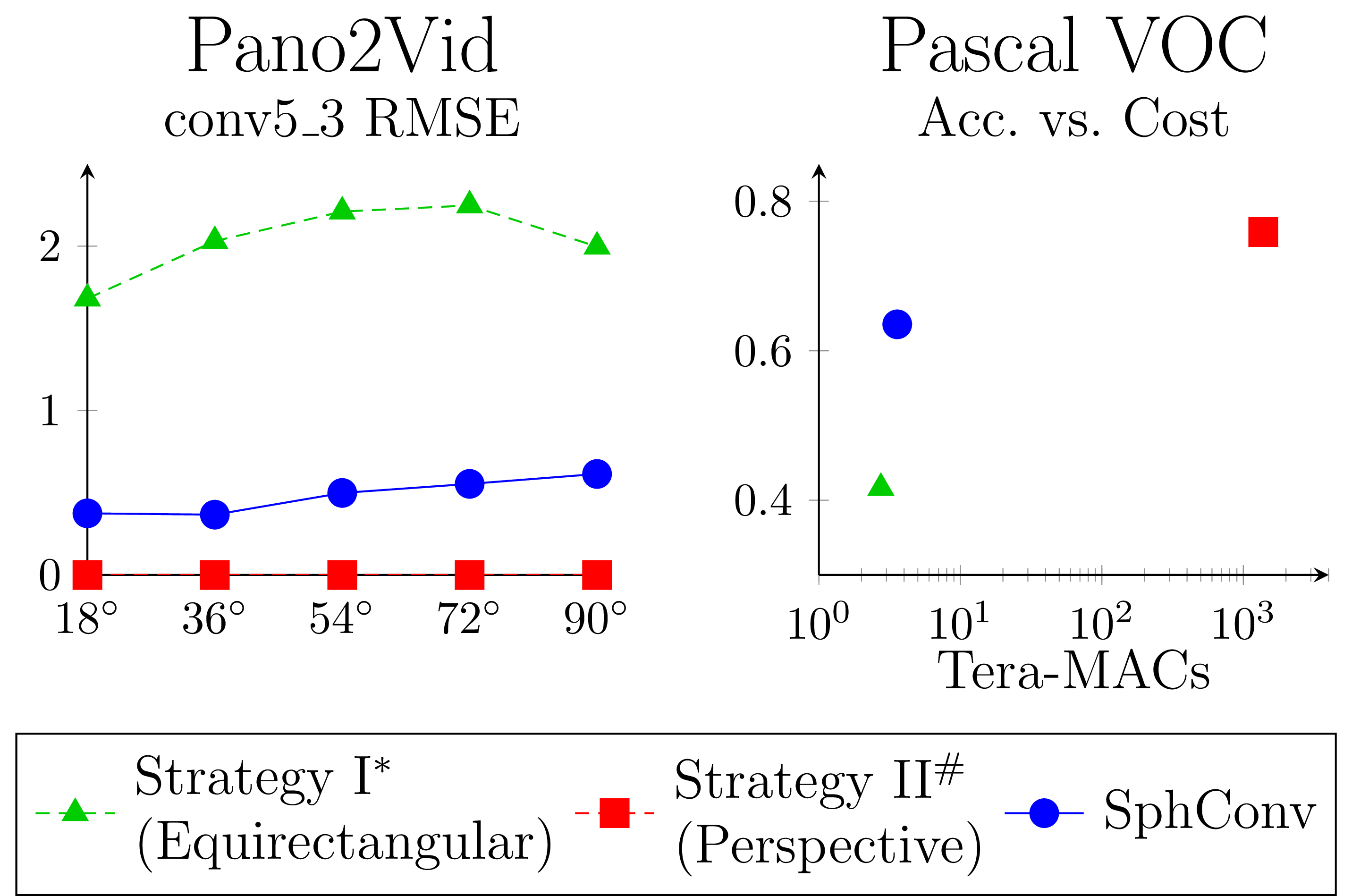
- Accuracy: SphConv is 50% more accurate than Strategy I
- Efficiency: SphConv is orders of magnitude faster than Strategy II
Example Outputs



